



EmoPrefer:大模型能理解人类对不同情感表示的偏好吗?
论文链接: https://openreview.net/pdf?id=EhA4znYsuG
代码链接:https://github.com/zeroQiaoba/AffectGPT/tree/master/EmoPrefer
论文作者:连政(同济大学)、孙立才、陈岚、陈皓宇、程泽浜、章帆、贾子钰、马子阳、马飞、彭小江、陶建华

描述性情感识别(DMER)旨在利用自然语言来描述人类的情感状态。与依赖预定义情感分类体系的传统判别式方法不同,DMER采用了一种生成式范式,为情感表征提供了更大的灵活性。这种方法能够实现更细粒度、更具可解释性的情感表达,为推动具备情感智能的人机交互技术发展带来了重要机遇。近年来,多模态大模型凭借其丰富的词汇量和强大的多模态理解能力,使得这一任务成为可能。图中展示了描述式与判别式多模态情感识别之间的区别。

图1任务对比。判别式情感识别是从预定义的情感分类体系中选择一个标签;描述式情感识别则通过纳入情感的时间动态变化、强度、不确定性以及多模态线索,提供更为详细和丰富的情感描述。
然而,评估此类开放式描述质量仍然是一项具有挑战性的任务。下图总结了现有的几种评估策略。第一种方法是利用真实情感描述,并借助大模型来衡量预测描述与真实描述之间的相似度。然而,情感本身与多种人类行为紧密相关,包括面部表情、(微)姿态、头部动作、手部动作以及语音语调等。因此,生成全面且准确描述情感状态的文本本身具有很大挑战,而不准确或不可靠的真实描述也会导致评估结果失真。为了解决这一问题,有研究者提出放弃那些成本高昂且往往不完整的真实描述,转而将“设计用于衡量与真实描述语义相似度的指标”这一复杂问题,重新表述为一个更易处理的“学习人类偏好”的问题。不过,这种方法需要对多个模型在多个样本上的每一对组合进行偏好标注,带来了巨大的标注成本。例如,假设有M个模型和N个样本,那么总共需要的比较次数为C(M,2)×N,即模型两两之间在每个样本上都要进行比较。
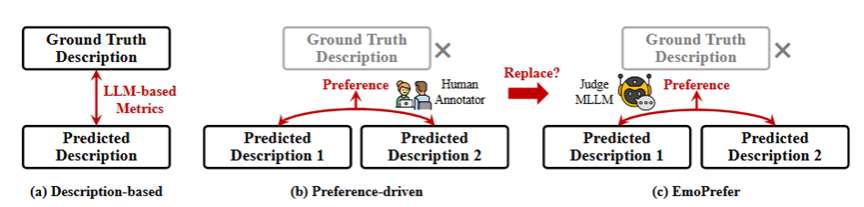
图2描述性多模态情感识别的评估策略。(a)基于描述的评估:该方法依赖成本高昂且通常不完备的人工标注描述;(b)基于偏好的评估:该方式需要进行成对的偏好标注,因而需要投入大量人工精力;(c)EmoPrefer方法:这是一项开创性的尝试,旨在探索多模态大模型是否能够解码人类的情感偏好,其目标是用基于大模型的判断替代昂贵的人工标注。
鉴于人工偏好标注成本高昂,一个启发性的想法应运而生:我们能否利用多模态大模型实现情感偏好的自动解码,从而为描述性多模态情感识别提供一种更具成本效益的评估策略?为了回答这一问题,我们提出了EmoPrefer——这是首个探索多模态大模型在情感偏好预测方面潜力的研究工作。(1)我们构建了EmoPrefer-Data,这是首个聚焦于人类情感的多模态偏好数据集。在该数据集中,我们为视频提供了成对的情感描述,并招募多位标注者对这些描述进行偏好标注。最终,仅保留所有标注者意见一致的样本,以确保偏好标注的质量。(2)我们建立了EmoPrefer-Bench,这是首个面向情感偏好预测的基准测试平台。在该基准中,我们对不同的多模态大模型及其提示策略进行了全面评估,并进一步探索了如何提升模型与人类偏好的一致性。本文是揭示多模态大模型在人类情感偏好理解方面能力的开创性工作。除了用于评估之外,本数据集及基准实验所获得的发现还将支持情感奖励模型的训练,增强多模态大模型与人类情感认知之间的一致性。本文的主要贡献总结如下:
(EmoPrefer) 这是一项开创性的研究,旨在探索多模态大模型在情感偏好理解方面的潜力。除评估功能外,本研究的洞见还将有助于训练能够理解人类情感的奖励模型,为构建具备情感智能的模型奠定基础。
(EmoPrefer-Data) 本文构建了首个以人类情感为核心、聚焦于偏好判断的数据集。本研究不仅将多模态场景拓展至涵盖音频、视频与文本的完整多模态环境,还将偏好学习引入人类情感领域,从而为当前LLM-as-Judge的研究做出贡献。
(EmoPrefer-Bench) 本文提出了全面的评估指标,并探索了多种解决方案,证明了针对人类情感进行自动偏好预测的可行性。
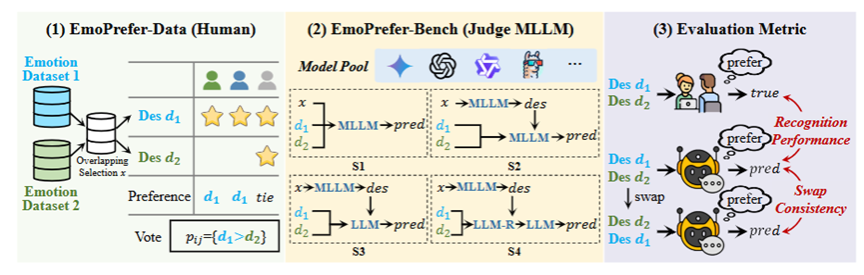
图3 EmoPrefer的工作流程。(1)EmoPrefer-Data:我们从两个描述性多模态情感识别数据集中筛选出重叠的视频样本,随后组织人工进行偏好标注,并采用多数投票结果作为最终的偏好标签。(2)EmoPrefer-Bench:我们系统性地评估了多种多模态大模型及其提示策略,揭示了它们在解码人类情感偏好方面的潜力。(3)评估指标:我们引入了两项性能评估指标。
作者简介:连政(IEEE/CCF Senior Member),现任同济大学副教授、博士生导师。近年来已在情感计算、人机交互、大模型等领域开展一系列研究工作,累计发表论文百余篇,包括TPAMI, TNNLS, TASLP, TAFFC等国际期刊和ICML, NeurIPS, ICLR等国际会议,Google Scholar 累计引用 5,500 余次(H-index: 39),入选全球前2%顶尖科学家榜单;获得中国电子学会技术发明一等奖;发布了多模态情感识别数据库MER,并围绕该数据库连续四年在ACM Multimedia 和 IJCAI上组织挑战赛和研讨会;担任IEEE Trans-AFFC/IEEE Trans-ASLP/PR Associate Editor,Information Fusion Area Editor,ACM Multimedia和 ACL ARR Area Chair,ACM Multimedia 2026 Dataset Co-Chair。
